
前言: 因为工作中经常要接触到 Pcap 这种文件格式,无论是利用其进行网络数据分析,还是测试时使用其进行流量回放。但是 Pcap 文件的底层数据结构是什么样子呢?里面装的又是什么东西呢?这是本文将要解答的两个核心问题
Pcap 是什么
Pcap 是 Packet Capture 的缩写,即网络数据包捕获。将捕获的数据包按照一定格式存入文件即 Pcap 文件。在 Linux 平台上使用 Tcpdump,在 Windows 上使用 Wireshark 抓包,可以保存为 .pcap 后缀的文件。
💡实际上 Pcap 文件存在多种格式,最常用的两种格式为 Libpcap 和 PcapNG(PCAP Next Generation) 格式,本文主要讲解 Libpcap 格式
Libpcap 格式最新草案:
- https://datatracker.ietf.org/doc/html/draft-ietf-opsawg-pcap
- https://github.com/IETF-OPSAWG-WG/draft-ietf-opsawg-pcap
Wireshark 说明:
- https://wiki.wireshark.org/FileFormatReference
- https://wiki.wireshark.org/Development/PcapNg
- https://wiki.wireshark.org/Development/LibpcapFileFormat
Pcap 文件的数据结构
文件整体格式
Pcap 文件由一个全局的头部(Global Header)和零至多个数据包(Packet,与网络层的 Packet 不是一个概念)组成,全局头部主要用于存储字节顺序、文件版本、单个数据包最大长度等信息。每一个数据包又由 Header 和 Data 组成,Header 中主要用于存储时间戳和 Data 的长度信息。
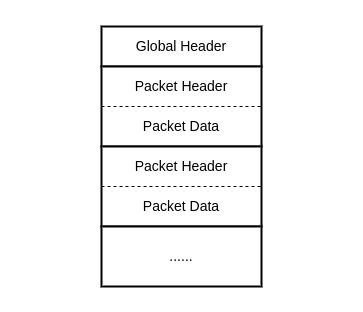
全局头部格式(Global Header)
现在来分析 Pcap 文件的全局头部,构造信息如下,每行 4 个字节(Byte)即 32 比特(bit),全局头部共计 24 个字节:
|
|
C 语言实现(来自Wireshark 文档),Github 上 Libpcap 的最新实现略有不同,不过无实质差别,具体见链接
|
|
相关字段解释如下表:
| 字段 | 字节数 | 含义 |
|---|---|---|
Magic Numbermagic_number |
4 | 十六进制数字0xA1 B2 C3 D4,标记文件开始,并用来识别文件的字节顺序。 |
Major Versionversion_major |
2 | 一个无符号值,给出 pcap 格式的当前主要版本的编号,一般为2。 |
Minor Versionversion_minor |
2 | 一个无符号值,给出 pcap 格式的当前次要版本的编号,一般为4。(与上面的 Major Version 一起组成版本号 2.4 ) |
ThisZonethiszone |
4 | 当地的标准时间,如果用的是UTC则全零,一般全零(在最新的标准中已弃用,因为现在都使用UTC时间,为向下兼容设置为全0) |
SigFigssigfigs |
4 | 时间戳的精度,一般全零(在最新的标准中已弃用,为向下兼容设置为全0) |
SnapLensnaplen |
4 | 设置所抓获的单个数据包的最大长度,一般设置为65535(单个数据链路层帧大小一般为1518字节包括14字节首部和4字节尾部,但是巨帧可达9000字节甚至更多,设置为65535大于任何标准或巨型以太网帧的大小,它提供了足够的空间来捕获几乎所有类型的网络数据包,包括非标准或实验性协议) |
LinkTypenetwork |
4 | 数据链路层协议类型。解析数据包首先要判断它的LinkType,所以这个值很重要。常见的值如 1,代表着以太网。相关定义和枚举值见参考链接 |
💡注意:对于 Magic Number,在其他地方或许会看到有人说除了0x A1 B2 C3 D4还有0x A1 B2 3C 4D,在较新的版本中确实存在A1 B2 3C 4D(大端模式)或者4D 3C B2 A1(小端模式)的情况,用于标记 Packet Header 中时间戳的精度为纳秒。
故从 Pcap 文件的低位到高位度读取,存在以下四种情况:
A1 B2 C3 D4:大端模式,Packet Header 中时间戳为毫秒精度D4 C3 B2 A1:小端模式,Packet Header 中时间戳为毫秒精度A1 B2 3C 4D:大端模式,Packet Header 中时间戳为纳秒精度4D 3C B2 A1:小端模式,Packet Header 中时间戳为纳秒精度
❗️ 网上的很多文档混淆了大小端和时间戳精度,注意甄别
在最新草案中,全局头部的最后四字节数据也有所变化,感兴趣的朋友可以自行查看
数据包头部格式(Packet Header)
数据包构造信息如下,每行 4 个字节(Byte)即 32 比特(bit),每个数据包头部共计 16 个字节:
|
|
C 语言实现(来自Wireshark 文档),Github 上 Libpcap 的最新实现略有不同,不过无实质差别,具体见链接
|
|
相关字段解释如下表:
| 字段 | 字节数 | 含义 |
|---|---|---|
Timestamp(Seconds)ts_sec |
4 | 秒级时间戳,秒值是一个 32 位无符号整数,表示自 1970 年 1 月 1 日 00:00:00 UTC 以来经过的秒数 |
Timestamp(Microseconds)ts_usec |
4 | 微秒值表示自秒值之后经过的微秒(可以理解为秒数小数点后的数) |
Captured Packet Lengthincl_len |
4 | 一个无符号值,表示从网络中实际中捕获的字节数(即 Packet Data 的长度)。它的值为原始数据包长度(Original Packet Length)和快照长度(上表中的 SnapLen)中的较小值。 |
Original Packet Lengthorig_len |
4 | 一个无符号值,表示数据包在网络上传输时的实际长度。如果数据包在捕获过程中被截断,则捕获的数据包长度与实际网络中传输的数据包长度不同。 |
Packet Datadata |
由上述 Captured Packet Length 字段决定 | 实际被捕获的数据链路层帧,包括链路层标头。该字段的实际长度为 Captured Packet Length。链路层头部的格式取决于文件全局头部中指定的 LinkType 字段。可以理解为:每一个 Packet 中都装着一个数据链层的帧。 |
使用 ImHex 查看 Pcap 包
经过上文的介绍我们知道了 Pcap 文件的全局头部格式和数据包头部格式,下面我们使用十六进制编辑器开始查看和分析一个实际的 Pcap 文件:
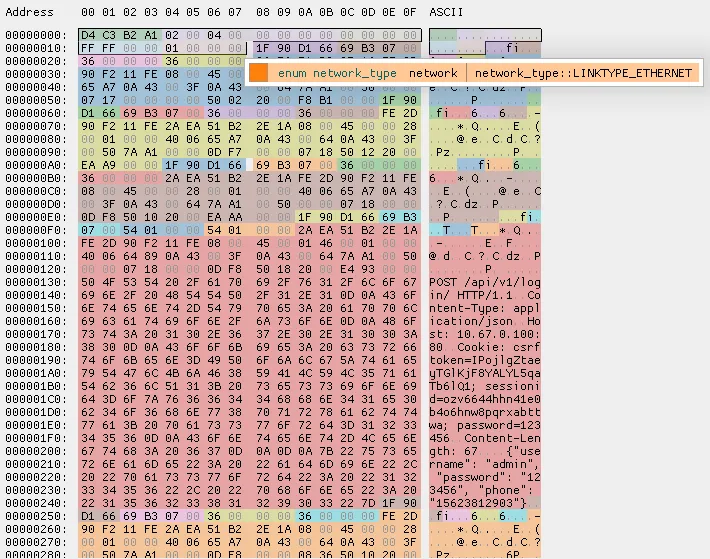
图 3.1:使用 ImHex 打开 Pcap 文件
全局头部
根据上述章节的分析可知全局头部占24个字节,于是让我们分析上述 Pcap 文件的前24个字节,如下图:

图 3.1.1:Pcap 文件的全局头部
具体内容如下:
|
|
前四个字节为 Magic Number,从低地址到高地址依次为 D4 C3 B2 A1,由上述章节可知该 Pcap 文件的字节顺序为小端序,那么对于多字节数据需要倒排字节才能得到实际的数据,具体数据转换如下表:
| 字段 | 字节序号 | 小端序数据 | 大端序数据 | 实际数据(由大端序计算) |
|---|---|---|---|---|
| Magic Number(4B) | 0-3 | 0xD4 C3 B2 A1 | 0xA1 B2 C3 D4 | LE 小端模式标记 |
| Major Version(2B) | 4-5 | 0x02 00 | 0x00 02 | 2 |
| Minor Version(2B) | 6-7 | 0x04 00 | 0x00 04 | 4 |
| ThisZone(4B) | 8-11 | 0x00 00 00 00 | 0x00 00 00 00 | 0 |
| SigFigs(4B) | 12-15 | 0x00 00 00 00 | 0x00 00 00 00 | 0 |
| SnapLen(4B) | 16-19 | 0xFF FF 00 00 | 0x00 00 FF FF | 65535 |
| LinkType(4B) | 20-23 | 0x01 00 00 00 | 0x00 00 00 01 | LINKTYPE_ETHERNET 以太网 |
数据包头部
根据上述章节可知,数据包头部为 16 字节,那么全局头后面的16个字节即为 Pcap 文件中第一个数据包的头部,如下图:

图 3.2.1:Pcpa 文件中第一个数据包的头部信息
具体信息如下:
|
|
依次分析,数据包头由四个字段组成,每个字段 4 个字节,具体数据转换如下表:
| 字段 | 字节序号 | 小端序数据 | 大端序数据 | 实际数据(由大端序计算) |
|---|---|---|---|---|
| Timestamp(Seconds)(4B) | 24-27 | 0x1F 90 D1 66 | 0x66 D1 90 1F | 1725009951 |
| Timestamp(Microseconds)(4B) | 28-31 | 0x69 B3 07 00 | 0x00 07 B3 69 | 504681 |
| Captured Packet Length(4B) | 32-35 | 0x36 00 00 00 | 0x00 00 00 36 | 54 |
| Original Packet Length(4B) | 36-39 | 0x36 00 00 00 | 0x00 00 00 36 | 54 |
秒级时间戳为 1725009951,微妙精度值为 504681,因此完整的秒级时间戳为1725009951.504691,转换为UTC +8时间为:2024-08-30 17:25:51
数据包捕获长度(Captured Packet Length)和网络上该包实际长度(Original Packet Length)是相同的说明网络上的数据包被完整捕获。意味着此 Packet Header 对应的 Packet Data 的长度为 54 字节。
数据包负载
由上述信息可知第一个 Packet 数据包的数据体长度为 54 字节,因此从该数据包包头的最后一个字节后向后读取 54 字节即为第一个 Packet 数据包的数据体。
循环上述流式读取过程(先读取全局头部 24 字节,读取Packet 数据包头部 16 字节,读取 Packet 包头(Packet Header)中字段 Captured Packet Length 记录长度的数据作为数据体(Packet Data),读取第二个包头,读取第二个数据体……)
这里的一个个 Packet 数据包,便对应着 Wireshark 工具中的一条条记录,现在让我们使用 ImHex 和 Wireshark 查看该 Pcap 文件中的第一个数据包的数据体:
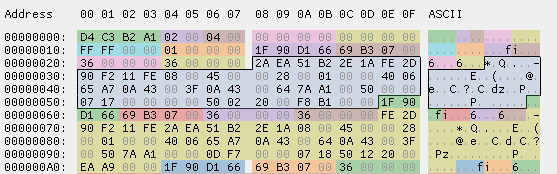
图 3.3.1 使用 ImHex 查看第一个数据包的数据体
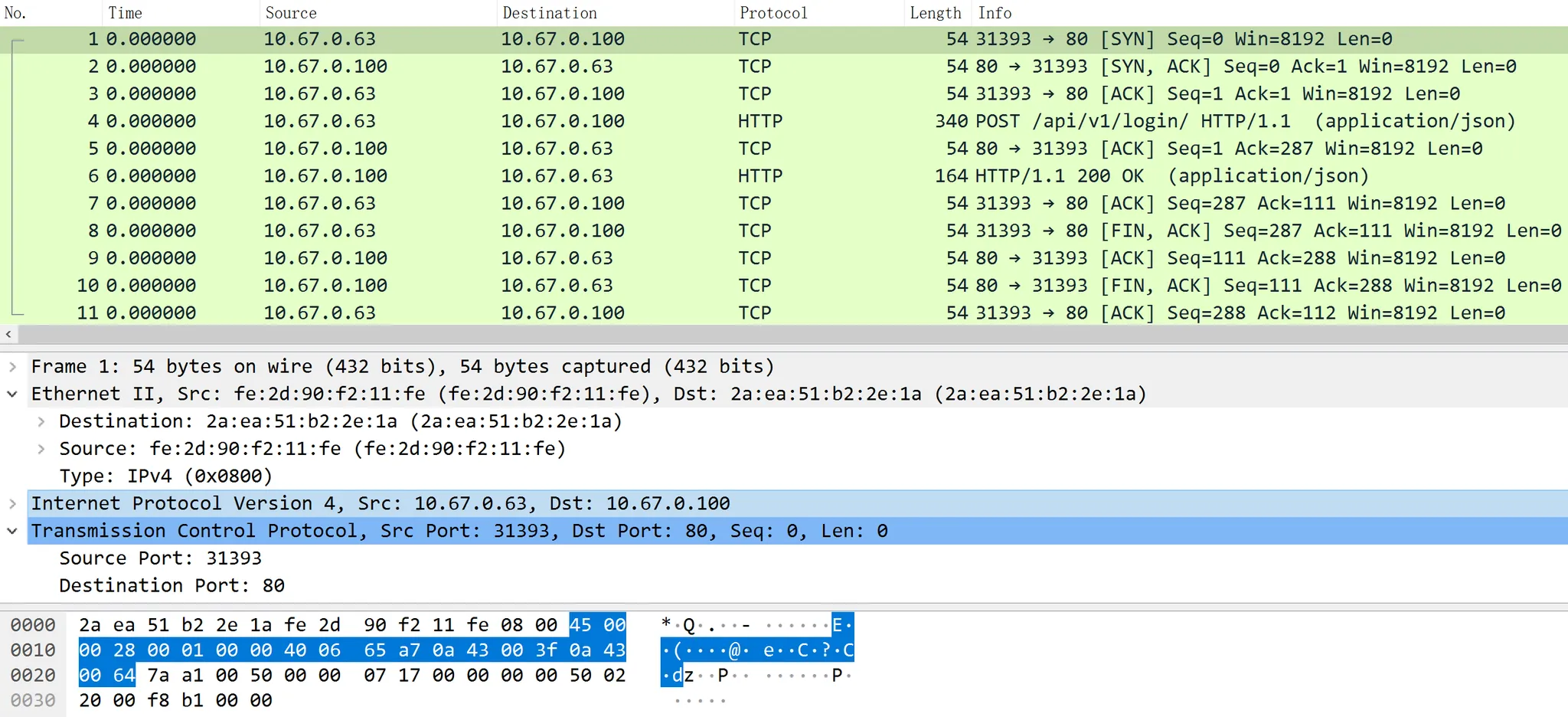
图 3.3.2 使用 Wireshark 查看第一个数据包
可以看出图 3.3.1 中选中的 54 字节数据,与图 3.3.2 中最下面显示的 54 字节数据一致。
那么这 54 字节数据是什么呢?以及为什么是 54 字节而不是其他数字呢?对网络比较熟悉的朋友可能已经知道答案了:54 = 14 + 20 + 20;下面让我们按照网络协议栈从上往下,来看看这里的 14 和 20 都是什么:
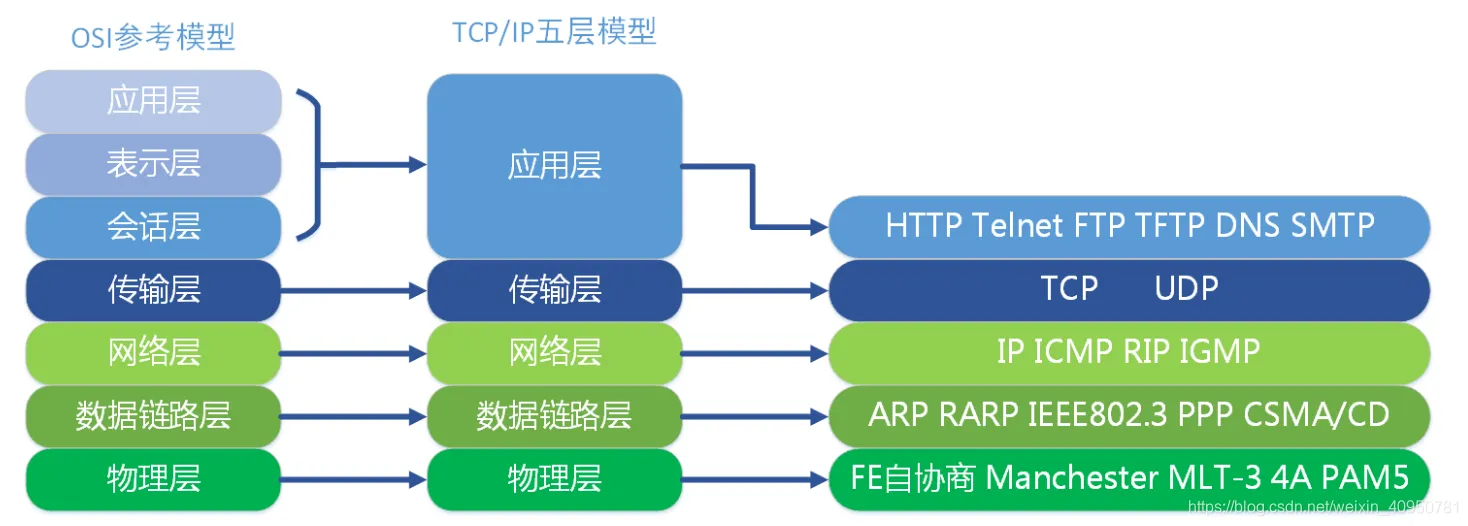
图 3.3.3 网络模型和协议
由上述图 3.3.2 Wireshark 的截图我们可知,第一个数据包捕获的内容即为 HTTP 协议在建立 TCP 连接前(HTTP 1.* 协议是基于 TCP 协议的)由客户端发起的第一个 ACK 请求。于是我们从 TCP 协议所在的传输层往下分析:
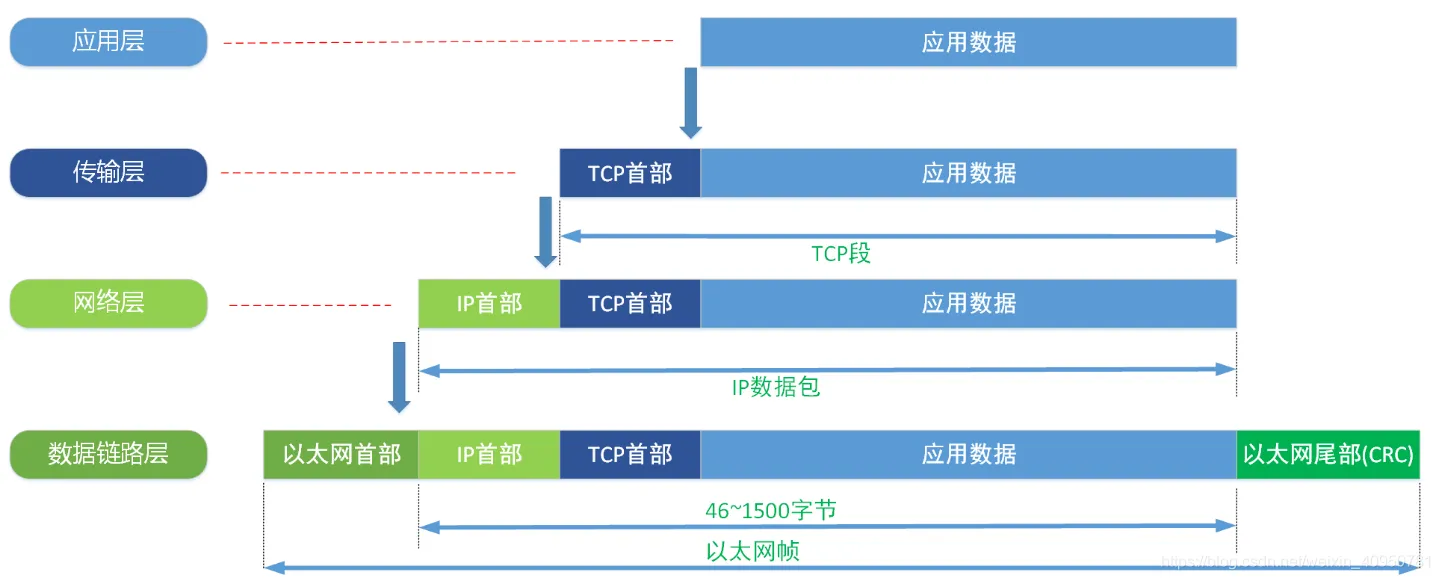
图 3.3.4 网络模型 数据发送流程中数据的传递过程
- 传输层:第一个数据包捕获的是 TCP 建立连接前的第一个由客户端发起的 ACK 请求,由于此次只使用到了 TCP 协议的头部,故为传输层的报文段(segment)的长度即为 TCP 协议头部的长度,即 20 字节。
- 网络层:上述传输层的报文向下交由网络层处理,网络层会为其增加一个网络层头部(20字节),然后继续向下层数据链路层传递。故而网络层封装好后数据包(Packet,这里的Packet指网络层数据包,与 Pcap 文件中的数据包为不同概念)大小为:
网络层数据包头长度(20 字节)+ 网络层数据包的数据体长度(20 字节)= 40 字节 - 数据链路层:上述网络层的数据包(40 字节)向下交由数据链路层处理,数据链路层会为其加上一个数据链路层头部(14 字节)和数据链路层尾部(FCS 即帧校验序列,4字节)进而组成一个数据链路层的帧。故而此帧的大小为:
帧头(14字节)+ 帧负载(40字节)+ 帧尾(4字节)= 54 + 4 = 58字节此时有朋友可能已经发现异常了,为什么我们上述 Pcap 文件中第一个数据包的数据体只有 54 字节,相比我们的计算值少了 4 个字节的数据,原因很简单因为数据链层的帧尾是由网卡负责处理的,网卡负责帧尾的计算和校验,在发送数据时网卡计算并添加帧尾后将数据发出,在收到数据时网卡校验并去除帧尾后再向上层传递,故而我们拿到的数据链路层帧其实是通过了帧尾校验并去除了帧尾之后的数据,所以就是58 - 4 = 54字节。
由上述信息可知,Pcap 文件中第一个数据包的 54 字节数据体中,前 14 字节为数据链路层头部,往后中间的 20 字节为网络层头部,最后 20 字节即为传输层头部(为什么只有头部没有数据体?因为TCP建立连接前的第一次 ACK 请求用不上数据体)。
这里我们就不再按照字节去分析链路层、网络层或是传输层的头部信息了,因为 Wireshark 已经可以很好的帮我们分析。有一个细节是,虽然该 Pcap 文件的字节序是小端序,但是在计算链路层、网络层等层的头部信息时,对于多字节字段不需要倒排字节,因为网络传输使用的是大端序,又因为 Pcap 文件中每一个数据包的数据体都是一个”数据链路层帧”,并未做其他转换,故而数据体中的数据也是大端序,在计算跨字节数据时不需要逆转字节顺序。
总结
至此我们完成了 Libpcap 格式的 Pcap 文件数据构造分析。并以一个实际的 Pcap 文件作为例子进行了对照学习。解答了前言中提出的问题:
-
Pcap 文件的数据构造?
Pcap 文件由一个 24 字节的全局头部(Global Header),和多个数据包(Packet)组成;每一个数据包又由 16 字节的头部(Packet Header)和数据体(Packet Data)组成,数据体的长度由头部字段 Captured Packet Length 记录;
-
Pcap 文件的数据包中的数据体(Packet Data)保存的是什么内容?
Pcap 文件中的每一个数据包对应 WireShark 中的一条记录;每一个数据包中的数据体对应一个捕获到的“数据链路层的帧”(无 FCS 帧尾);
本文并未提及 Pcap 包的捕获和回放方法,感兴趣的读者可以自行检索,具体实现方法包括但不限于:原始套接字、DPDK、XDP